일반적인 크롤링으로는 정적 데이터, 즉 변하지 않는 데이터만을 수집할 수 있습니다.
정적 데이터는 한 페이지 안에서 원하는 정보가 모두 드러나는 것을 정적 데이터라고 합니다.
이와 달리, 입력, 로그인 등을 통해 데이터가 바뀌는 것을 동적 데이터라고 합니다.
예를 들어서, 네이버 지도에서 카페를 입력하여 지도에 표시되는 카페들을 클릭한다고 합시다.
이때 다른 카페를 클릭할 때 페이지가 전환되는게 아니라 같은 페이지에서 내용만 변경됩니다.
이러한 데이터가 동적 데이터입니다.
셀레니움을 이용하면 정적 데이터, 동적 데이터 모두 크롤링 가능하지만 상대적으로 속도가 느립니다.
그래서 일반적으로 정적 크롤링 할때는 일반적인 request 패키지를 이용하고, 동적 클롤링은 셀레리움을 이용합니다.
#동적 크롤링 실습
먼저 실습 전에 필요한 라이브러리를 다운 받아야 합니다.
selenium과 webdriver-manager입니다
설치 안되어 있으신 분들은 터미널에
pip install selenium 그리고 pip install webdriber-manager를 작성하여 설치해주세요.
그리고 이제 필요한 패키지들을 불러와 봅시다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
import time
from bs4 import BeautifulSoup
페이지를 켜봅시다.
driver = webdriver.Chrome()
여기까지 실행하면 빈 페이지가 켜졌다가 바로 꺼지는 것을 확인하실 수 있습니다.
페이지를 계속 켜두기 위해 input 함수를 통해 제어해 봅시다.
아래의 코드는 전체 코드 맨 아래에 위치해 두세요
#페이지 꺼짐 방지
a = True
while (a):
b = input("break: ")
if (b == "break"):
a = False
이번에는 naver로 이동하여 해당 페이지의 html 정보를 얻어 봅시다.
조금 전에 작성해 두었던 driver = webdriver.Chrome() 아래에 다음 코드를 작성해 주세요.
#해당 주소로 이동
url = 'https://www.naver.com'
driver.get(url)
#로딩 다 될때까지 기다리기
time.sleep(2)
#해당 페이지 html 정보
print(driver.page_source)
이번에는 뉴스 버튼을 클릭해 봅시다.
브라우저 상에서 보이는 버튼, 검색창, 사진, 테이블, 동영상 등을 엘레먼트(element)라고 합니다.
find_element() 함수는 다양한 방법으로 엘레멘트에 접근하게 해주며
By. ~ 를 통해 어떠한 방법으로 엘레먼트에 접근할지 선언합니다.
LINK_TEXT의 경우 링크가 달려 있는 텍스트로 접근합니다.
CLASS_NAME은 class 이름을 찾아서 접근합니다. 마지막의 click() 함수를 통해 해당 엘레멘트를 클릭합니다.
#뉴스 버튼 클릭
driver.find_element(By.CLASS_NAME, value = 'type_news').click()
#검색창에 검색어 입력우 검색하기
이번에는 검색창에 키워드를 입력후 검색까지 해보겠습니다.
#특정 검색어 검색하기
driver.find_element(By.CLASS_NAME, value = 'search_input').send_keys('파이썬')
driver.find_element(By.CLASS_NAME, value = 'ico_btn_search').click()
이번에는 기존 검색어 지우고 새로 키워드 입력후 검색해보겠습니다.
#기존 검색어 지운 후 새로운 단어 입력하고 검색버튼 클릭
time.sleep(1) #로딩 대기
driver.find_element(By.CLASS_NAME, value = 'box_window').clear()
driver.find_element(By.CLASS_NAME, value = 'box_window').send_keys('c++')
driver.find_element(By.CLASS_NAME, value = 'bt_search').click()
#XPATH
이번에는 XPATH를 이용해 'view' 버튼을 눌러보겠습니다.
XPATH란 HTML이나 XML중 특정 값의 태그나 속성을 찾기 쉽게 만든 주소입니다.
view 우클릭 -> 검사 -> 해당하는 태그 우클릭 -> copy -> copy XPath
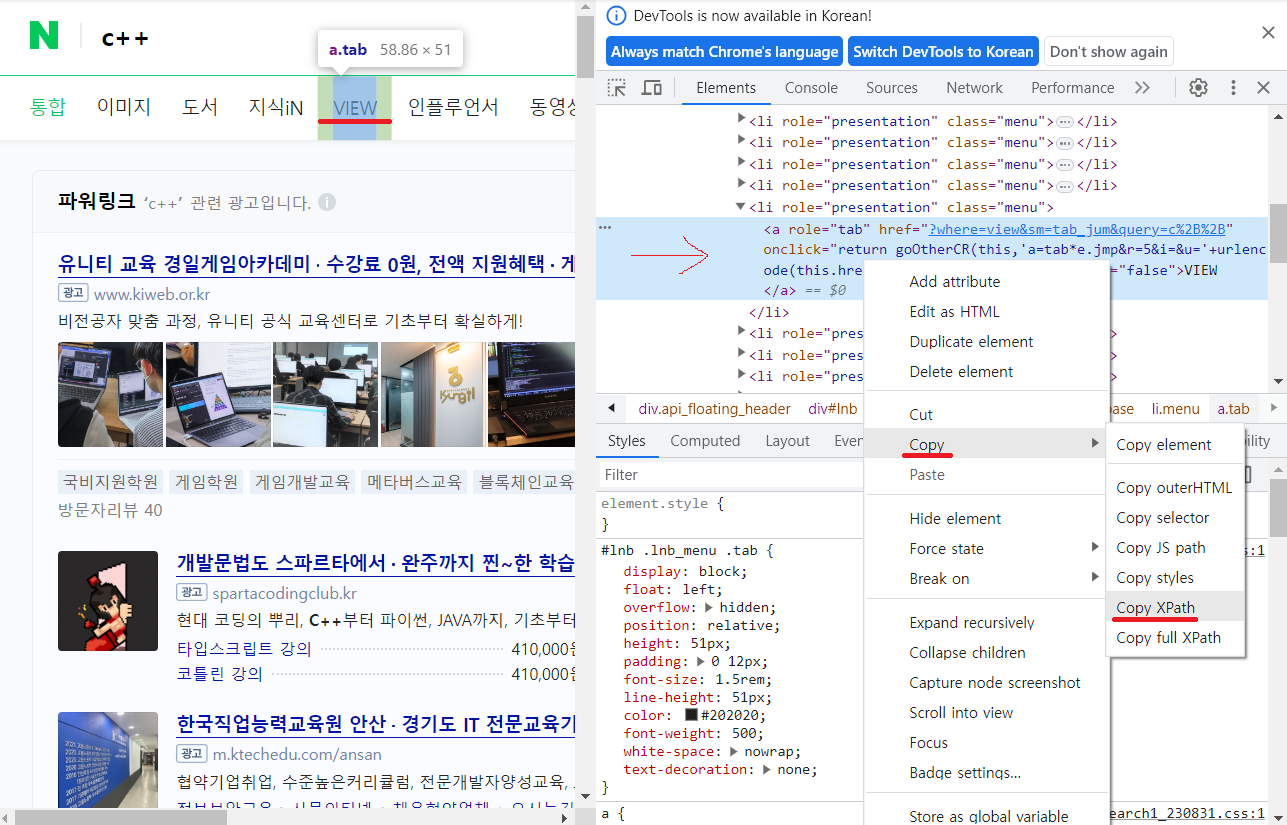
find_element를 하는데 By.XPATH를 해주세요. 그리고 복사한 xpath를 value에다가 붙여넣어주시면 됩니다.
driver.find_element(By.XPATH, value = '//*[@id="lnb"]/div[1]/div/ul/li[5]/a').click()
#페이지 스크롤 다운
이번에는 페이즈 스크롤 다운 해보겠습니다.
#execute_script를 통해 js 명령어 실행
#화면 하단 끝까지 scroll
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
또한 아래 코드로도 가능합니다.
driver.find_element(By.TAG_NAME, value = 'body').send_keys(Keys.PAGE_DOWN)
이렇게 셀레니움을 통해 브라우저를 제어할 수 있습니다.
이렇게 제어후 크롤링 해주시면 됩니다.
'파이썬으로 퀀트 프로그램 만들기 project > 웹 크롤링' 카테고리의 다른 글
| 국내 주식 재무제표 크롤링하기_1 (2) | 2023.09.24 |
|---|---|
| 국내 주식 섹터 데이터 크롤링 (2) | 2023.09.06 |
| 웹 크롤링 실습_6 - POST (0) | 2023.09.04 |
| 웹 크롤링 실습_5 - 테이블 데이터 크롤링 하기(pandas) (0) | 2023.09.04 |
| 웹 크롤링 실습_4 - 금융 속보 제목 추출하기 (0) | 2023.09.04 |


