728x90
웹 크롤링 방식 중 POST 방식으로 실습을 진행해보겠습니다.
예시 웹 사이트로 한국거래소 상장공시시스템에 접속해주세요.
그리고 [오늘의 공시 -> 전체 -> 더보기]를 선택하면 전체 공시내요을 확인할 수 있습니다. (링크)
여기서 다른 날짜를 검색해도 페이지는 바뀌지만 URL은 바뀌지 않는 것을 확인할 수 있습니다.
POST방식인 것을 확인할 수 있습니다.
개발자도구 화면을 열고 [Network] 클릭 후, 오늘의 공시에 날짜를 클릭하면 todaydisclosure.do
를 확인할 수 있습니다.
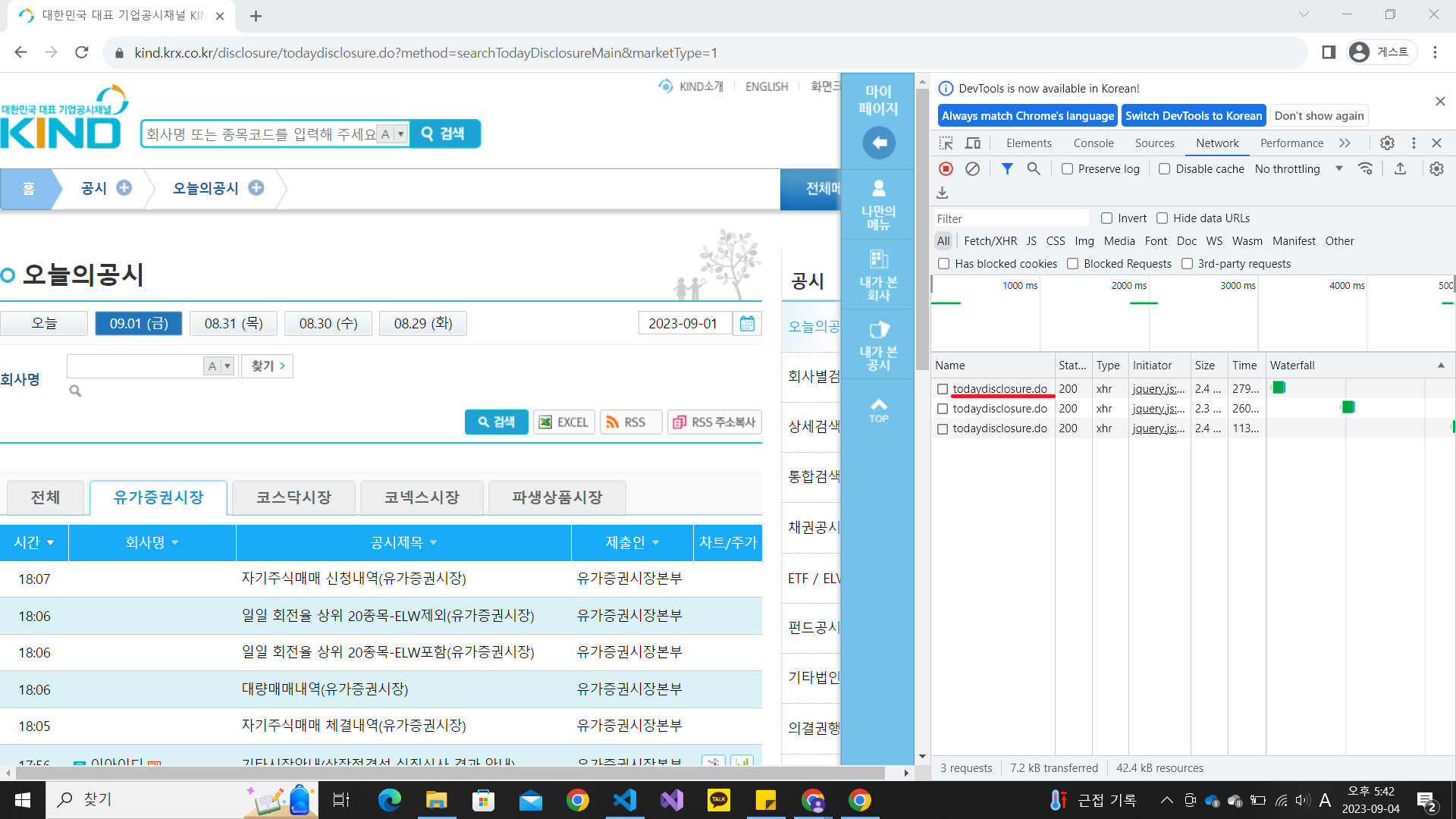
todaydisclosure.do를 통해 데이터를 요청하는 것입니다. 그것을 클릭하여 [Headers]를 보시면 Request URL이 우리가 요청하는 주소이고, Request method가 POST방식임을 확인할 수 있습니다.

그리고 [Payload] 에서 [Form Data]를 틍호 서버에 데이터를 요청하는 내역을 확인할 수 있습니다.
여기서 selDate 부분이 우리가 선택한 날짜에 해당합니다.

위와 같은 정보들을 이용하여 POST 방식으로 크롤링 해보겠습니다.
import requests as rq
from bs4 import BeautifulSoup
import pandas as pd
#Headers 부분에 Request URL
url = 'https://kind.krx.co.kr/disclosure/todaydisclosure.do'
#값이 없는 항목은 입력 안해도 된다.
payload = {
'method': 'searchTodayDisclosureSub',
'currentPageSize': '15',
'pageIndex': '1',
'orderMode': '0',
'orderStat': 'D',
'forward': 'todaydisclosure_sub',
'chose': 'S',
'todayFlag': 'N',
'selDate': '2023-08-30'
}
data = rq.post(url, data = payload)
html = BeautifulSoup(data.content)
print(html)
결과를 보면 예상보다 복잡한 결과가 출력됩니다. 이것은 엑셀 데이터가 HTML 형태로 나와있기 때문입니다.
이것을 변형하여 데이터프레임 형태로 불러오도록 하겠습니다.
#BeautifulSoup 에서 파싱한 파서트리를 prettify()함수를 통해
#다시 유니코드 형태로 돌려줍니다.
html_unicode = html.prettify()
tbl = pd.read_html(html_unicode)
print(tbl)
테이블은 pandas를 통해 쉽게 불러올 수 있습니다.
'파이썬으로 퀀트 프로그램 만들기 project > 웹 크롤링' 카테고리의 다른 글
| 국내 주식 섹터 데이터 크롤링 (2) | 2023.09.06 |
|---|---|
| 동적 크롤링 - 셀레니움 (0) | 2023.09.05 |
| 웹 크롤링 실습_5 - 테이블 데이터 크롤링 하기(pandas) (0) | 2023.09.04 |
| 웹 크롤링 실습_4 - 금융 속보 제목 추출하기 (0) | 2023.09.04 |
| 웹 크롤링 실습_3 (0) | 2023.09.04 |


