웹 크롤링을 처음 배우신 분들은 저번 포스트를 참조해주세요.
일반적인 크롤링 과정은 다음과 같습니다.
1. HTML 정보 받기
request 패키지의 get() 혹은 post() 함수를 이용해 데이터를 요청한 후 HTML정보를 가져옵니다.
2. 태그 및 속성 찾기
bs4 패키지의 함수들을 이용해 원하는 데이터를 찾습니다.
3. 클렌징
데이터 클렌징
#크롤링할 데이터의 태그
이제 크롤링 실습을 해보겠습니다. 웹 크롤링 연습으로 자주 사용되는 명언 인용 사이트를 이용하겠습니다.
먼저 크롤링을 하기 위해서는 우리가 가져오고 싶은 데이터가 어떤 태그에 위치하는지 알아야 합니다.
이를 위해 [F12] 키를 눌러 개발자도구 화면을 열고 [Elements]탭을 선택합니다. 그리고 마우스 우클릭 후 [검사]를 눌러보면 HTML 태그가 열립니다. 그리고 마우스로 위아래로 움직여 보면 태그에 해당하는 것이 화면에 어떤 부분인지 표시가 됩니다.
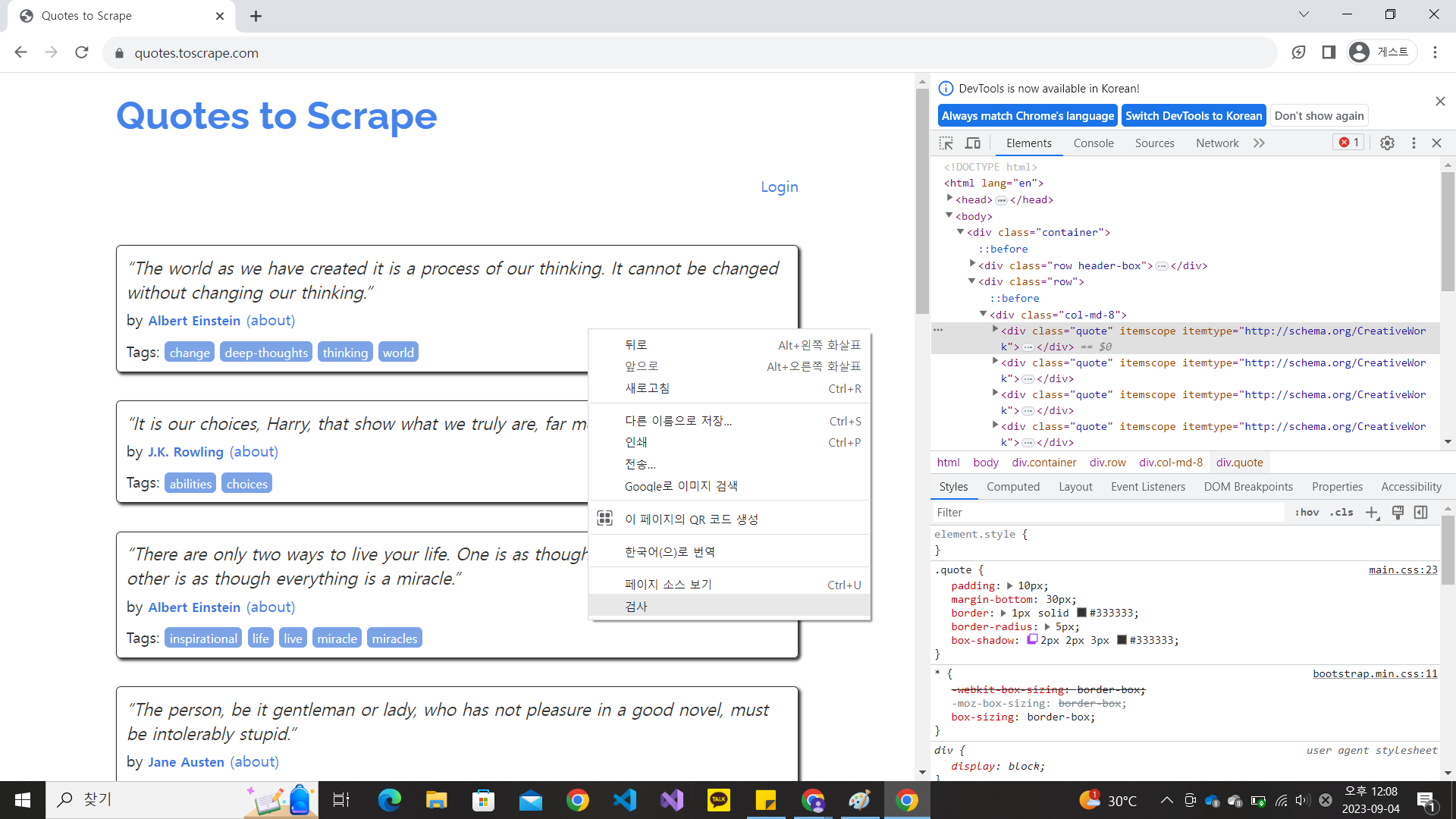
각 네모에 해당하는 부분은 div 태그 중 class 이름이 quote인 부분임을 알 수 있습니다.
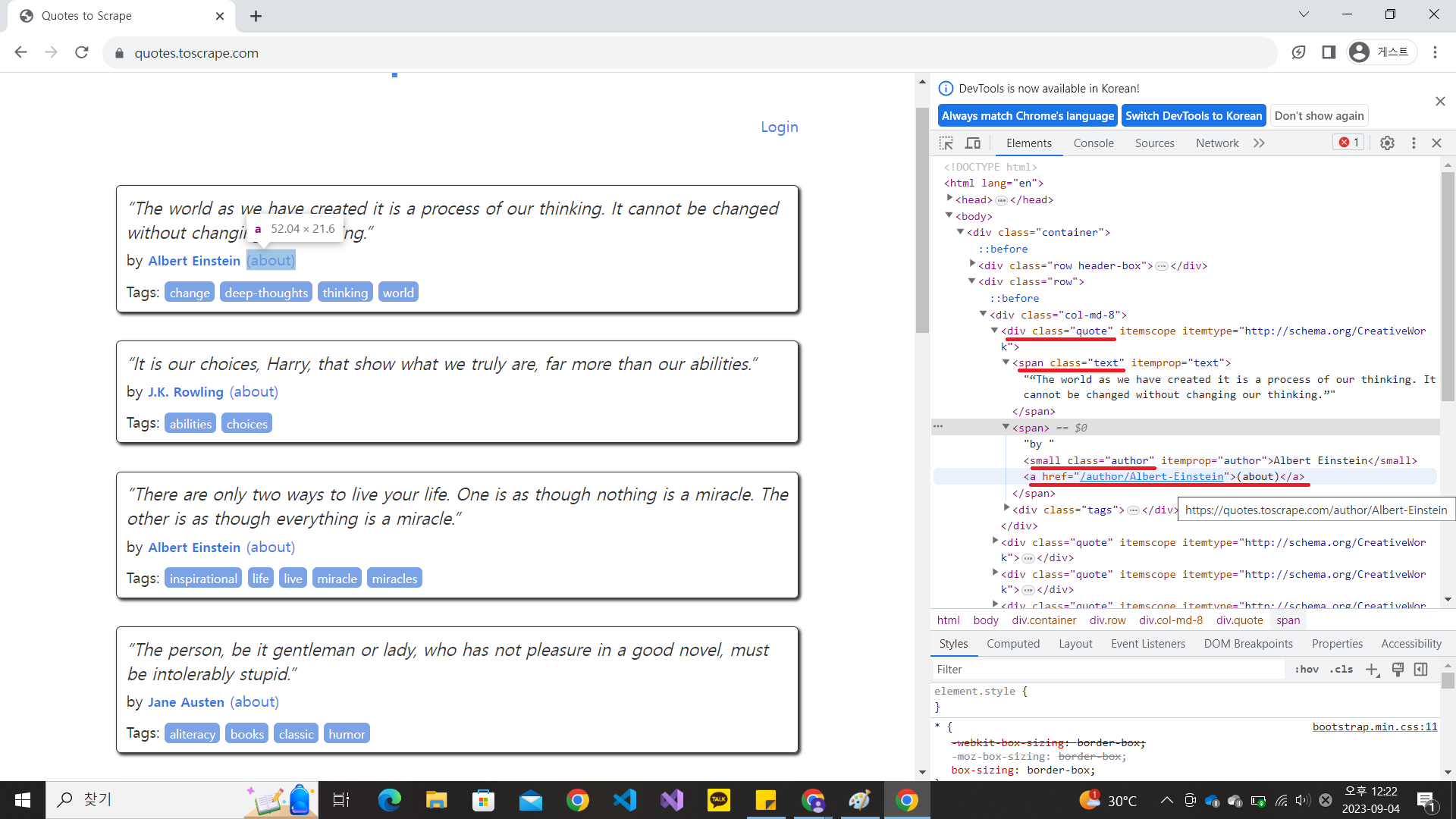
명언에 해당하는 부분은 위의 태그 하분의 span 태그 중 class 이름이 text인 부분임을 알 수 있습니다.
말한 사람은 span 태그 하단의 small 태그 중 class 이름이 author인 부분입니다.
말한 사람에 대한 정보인 about의 링크는 a 태그에 href 속성의 속성값으로 링크가 걸려있습니다.
#python 실습
이제 python으로 크롤링 실습을 해보겠습니다.
import requests as rq
url = 'https://quotes.toscrape.com/'
quote = rq.get(url) #GET 방식
print(quote) #<Response [200]>
print(quote.content) #텍스트 형태의 HTML 정보
print(quote)의 결과로 <Response [200]>이 뜰 것입니다. HTTP 상태코드 200은 응답을 정상적으로 처리했다는 뜻입니다.
print(quote.content)의 결과로 텍스트 형태의 html 정보가 뜹니다. 그러나 이것은 텍스트 형태이므로 크롤링 하기 불편합니다. 아래와 같이 크롤링 하기 좋은 형태로 바꿔야 합니다.
import requests as rq
url = 'https://quotes.toscrape.com/'
quote = rq.get(url) #GET 방식
from bs4 import BeautifulSoup
#HTML 요소에 접근하기 쉬운 BeautifulSoup 객체로 변경
quote_html = BeautifulSoup(quote.content, features = "html.parser")
print(quote_html) #확인여기서 UnicodeEncodeError: 'cp949' codec can't encode character 가 뜨시는 분은 다음 링크를 통해 해결해주세요.
이제 명언에 해당하는 부분을 크롤링 해보겠습니다.
명언 부분은 [class가 quote인 div 태그] 아래에 [class가 text인 span태그]에 있었습니다.
find_all함수를 통해 특정 태그에 특정 class에 접근이 가능합니다.
#div 태그에서 class가 quote인 것에 접근
quote_div = quote_html.find_all('div', class_ = 'quote')
# 1번째 하부에 span태그에 class가 text인것에 접근
# -> 리스트 속 0번째 인덱스에 text 를 통해 text만 뽑아내기
text_1 = quote_div[0].find_all('span', class_ = 'text')[0].text
print(text_1)
이제 사이트에서 명언 부분들만 한 번에 추출해보겠습니다. for문을 통해 한번에 가능합니다.
quote_list_1 = [ i.find_all('span', class_ = 'text')[0].text for i in quote_div]
print(quote_list_1)
지금까지의 경우는 html 구조가 간단하여 태그를 두 번만 타고 들어가면 됐지만 html 구조가 복잡한 경우
이처럼 find_all()함수로 태그를 하나하나 들어가기 어려울 것입니다.
이때는 select() 함수를 사용할 수 있습니다.
#find_all() 함수 대신에 select() 함수 이용하여 데이터 한번에 접근하기
quote_text = quote_html.select('div.quote > span.text')
quote_list_2 = [i.text for i in quote_text]
print(quote_list_2)
'파이썬으로 퀀트 프로그램 만들기 project > 웹 크롤링' 카테고리의 다른 글
| 웹 크롤링 실습_5 - 테이블 데이터 크롤링 하기(pandas) (0) | 2023.09.04 |
|---|---|
| 웹 크롤링 실습_4 - 금융 속보 제목 추출하기 (0) | 2023.09.04 |
| 웹 크롤링 실습_3 (0) | 2023.09.04 |
| UnicodeEncodeError: 'cp949' codec can't encode character 해결 (0) | 2023.09.04 |
| 웹 크롤링 실습_1 - GET, POST (0) | 2023.09.04 |

