크롤링 혹은 스크랩핑이란 웹 사이트에서 원하는 정보를 수집하는 기술을 뜻합니다.
크롤링을 할때의 주의사항이 있습니다.
#주의사항
· 특정 웹사이트의 페이지를 쉬지 않고 크롤링 하는 행위를 무한 크롤링이라고 합니다.
· 무한 크롤링은 해당 웹사이트의 자원을 독점하게 되어 타인의 사용을 막게 되며 웹사이트에 부하를 줍니다.
· 일부 웹사이트에서는 동일한 ip로 쉬지 않고 크롤링을 할 경우 접속을 막아버리는 경우도 있습니다.
· 따라서 하나의 페이지를 크롤링한 후 1~2초 가량 정지하고 다시 다음 페이지를 크롤링하는 것이 좋습니다.
· 신문기사나 책, 논문, 사진 등 저작권이 있는 자료를 통해 부당이득을 얻는다는 등의 행위를 할 경우 법적 제재를 받을 수 있습니다.
#GET
서버에 데이터를 요청하는 형태는 매우 다양하지만 크롤링에서는 주로 "GET"과 "POST"방식을 씁니다.
먼저 GET방식부터 알아보겠습니다.
GET방식: 인터넷 주소를 기준으로 이에 해당하는 데이터나 파일을 요청하는 것입니다.
주로 클라이언트가 요청하는 쿼리를 앰퍼센드(&) 혹은 물음표(?) 형식으로 결합해 서버에 전달합니다.
예를 들어 네이버 사이트에서 "웹 크롤링"이라고 검색해보면 주소 끝 부분에 &query=웹+크롤링이 입력되고 이에 해당하는 페이지 내용을 보여줍니다.
이것을 통해 네이버는 GET 방식을 사용하고 있음을 알 수 있고 입력종류는 query, 입력값은 웹 크롤링임을 알 수 있습니다.
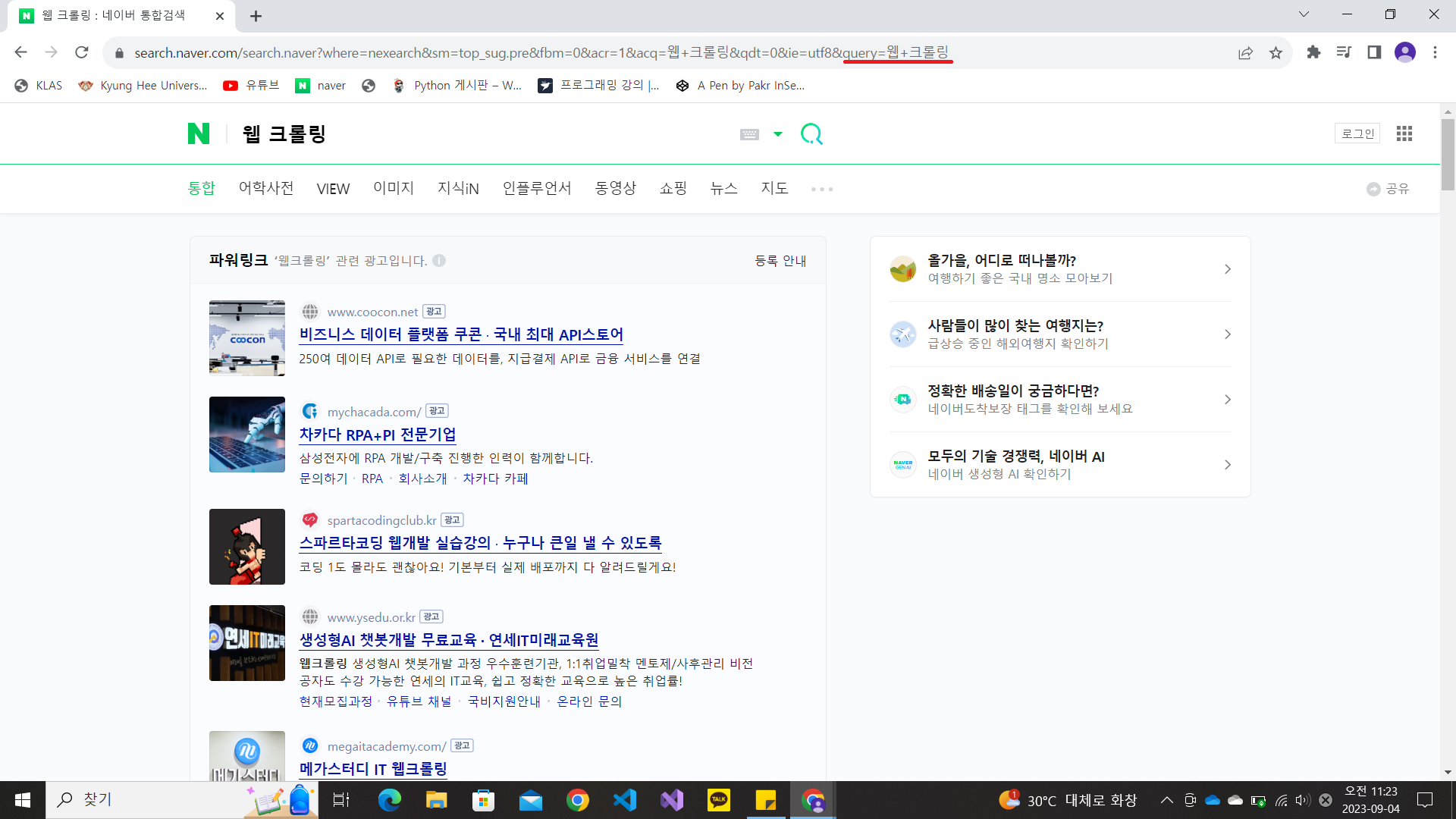
여기서 다시 검색창에 스크랩핑을 쳐봅시다.
URL이 &query=스크랩핑&oquery=웹+크롤링 으로 변경된 것을 알 수 있습니다.

이것을 이용하면 URL을 통해서도 검색이 가능합니다. query= 부분에 다름 키워드를 입력하면 해당하는 페이지로 이동할 수 있습니다.
#POST
POST 방식: 사용자가 필요한 값을 추가해서 요청하는 방법
GET 방식과 달리 클라이언트가 요청하는 쿼리를 body에 넣어서 전성하므로 요청 내역을 직접 볼 수 없습니다.
예를 들어 동행복권 사이트에서 [당첨결과] -> [회차별 당첨번호] 로 간 다음에 원하는 회차를 선택하고 조회를 해보면 해당 회차 당첨 결과가 나옵니다. 이때 인터넷 주소는 바뀌지 않고 페이지 내용만 바뀌는 것을 알 수 있습니다.
GET 방식에서는 입력 항목에 따라 웹페이지 주소가 변경되었지만 POST 방식을 사용해 서버에 데이터를 요청하는 웹사이트는 그렇지 않음을 알 수 있습니다.
POST 방식의 데이터 요청 과정을 살펴보려면 개발자도구를 이용해야 하며 크롬에서 [F12]키를 눌러 개발자도구 화면을 열 수 있습니다. 이것을 연 상태에서 당첨번호를 조회를 눌러주세요. 그리고 개발자도구 화면에서 [Network] 를 선택해 줍니다. 여기서 브라우저와 서버 간의 통신 과정을 살펴볼 수 있습니다.
여기서 맨위의 gameResult.do?method=byWin는 당첨 번호를 요구하는 것입니다. 이것을 클릭하고 [Headers]를 보면
Request URL, 서버주소를 확인할 수 있고 Request Method, 요청 방식이 POST라는 것을 알 수 있습니다.

그리고 [Payload]탭 에서 [Form Data]에는 서버에 데이터를 요청하는 내역이 있습니다. 거기에 있는 1080 두 번호가 우리가 요청한 당첨 번호입니다.

'파이썬으로 퀀트 프로그램 만들기 project > 웹 크롤링' 카테고리의 다른 글
| 웹 크롤링 실습_5 - 테이블 데이터 크롤링 하기(pandas) (0) | 2023.09.04 |
|---|---|
| 웹 크롤링 실습_4 - 금융 속보 제목 추출하기 (0) | 2023.09.04 |
| 웹 크롤링 실습_3 (0) | 2023.09.04 |
| 웹 크롤링 실습_2 - find_all(), select() (0) | 2023.09.04 |
| UnicodeEncodeError: 'cp949' codec can't encode character 해결 (0) | 2023.09.04 |

